Search is a component of most web sites. Therefore, it is a problem solved many times before. The solution of choice (at least in the Java sphere) is Lucene. Insert documents in an index, build queries to find the ones you want. Lucene is a library, so there are a bunch of other tools that wrap Lucene for easier interaction.
Use Solr, use elasticsearch, use Lucene directly – you still have to figure out two things: get your documents into the index, and get the relevant ones out. This post is about getting them out in an ordinary site-search sort of scenario.
For our purposes here, the documents have been indexed with default elasticsearch mappings. This means their fields have passed through the default analyzer, which breaks them down into terms (words), puts these in lowercase, and throws some extremely common words (stop words). The search text will go through the same default analyzer so that we’re comparing apples to apples, and not Apples or APPLES or “apples and oranges.”
What does a reasonable Lucene-style query for site search look like? There’s documentation out there about the query API, all about what to type when you know what kind of query you want – but what kind of query do I want?
Our indexed documents each have two fields: name and description. The search match some text against both fields. Handle some misspellings or typos. Emphasize exact matches in the name field. This seems pretty straightforward, but it isn’t trivial. It involves a compound query combining an exact phrase match, exact term matches, and fuzzy term matches.
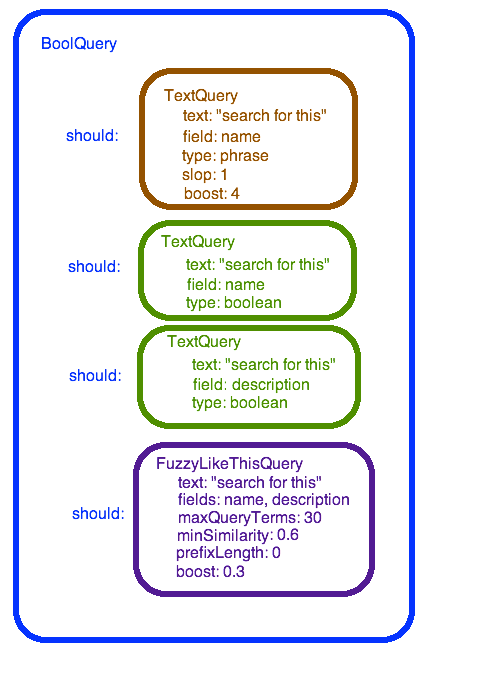
BoolQuery
The outer query is a BoolQuery. A BoolQuery is more complex than AND/OR logic, because there’s more to a query than a “yes” or “no” on each document — there is an ordering to the results.
There are three ways to construct a BoolQuery:
- only “must” components. This is like a big AND statement: each record returned matches every “must” query component.
- only “should” components. This is a lot like an OR statement; each record returned matches at least one of the “should” query components. The more “should” components that match the record, the higher the record’s rank.
- a mix of “must” and “should” components. In this case, the “must” clauses determine which records will be returned. The “should” components contribute to ranking.
For the simplest site search, all the different text queries go in as “should” components. We’re taking the giant-OR route.
Phrase Query
The first subquery is a TextQuery with type “phrase.” This is elasticsearch parlance; Lucene has a PhraseQuery. The objective here is to find the exact phrase the user typed in. A slop of 1 means there can be one extra word in between the words in the phrase. Increasing the slop to 2 will match two-word phrases with the words out of order. Adding a boost of 4 tells Lucene that this query is 4 times as important as the other queries.
Text Query
FuzzyLikeThis
If you have any suggestions to make this better, please, leave a comment.