Can you take a piece of data in your system and say what version of code put it in there, based on what messages from other systems? and what information a human viewed before triggering an action?
Me neither.
Why is this acceptable? (because we’re used to it.)
We could make this possible. We could trace the provenance of data. And at the same time, mostly-solve one of the challenges of distributed systems.
Speaking of distributed systems…
In a distributed system (such as a web app), we can’t say for sure what events happened before others. We get into general relativity complications even at short distances, because information travels through networks at unpredictable speeds. This means there is no one such thing as time, no single sequence of events that says what happened before what. There is time-at-each-point, and inventing a convenient fiction to reconcile them is a pain in the butt.
We usually deal with this by funneling every event through a single point: a transactional database. Transactions prevent simultaneity. Transactions are a crutch.
Some systems choose to apply an ordering after the fact, so that no clients have to wait their turn in order to write events into the system. We can construct a total ordering, like the one that the transactional database is constructing in realtime, as a batch process. Then we have one timeline, and we can use this to think about what events might have caused which others. Still: putting all events in one single ordering is a crutch. Sometimes, simultaneity is legit.
When two different customers purchase two different items from two different warehouses, it does not matter which happened first. When they purchase the same item, it still doesn’t matter – unless we only find one in inventory. And even then: what matters more, that Justyna pushed “Buy” ten seconds before Edith did, or that Edith upgraded to 1-day shipping? Edith is in a bigger hurry. Prioritizing these orders is a business decision. If we raise the time-ordering operation to the business level, we can optimize that decision. At the same time, we stop requiring the underlying system to order every event with respect to every other event.
On the other hand, there are events that we definitely care happened in a specific sequence. If Justyna cancels her purchase, that was predicated on her making it. Don’t mix those up. Each customer saw a specific set of prices, a tax amount, and an estimated ship date. These decisions made by the system caused (in part) the customer’s purchase. They must be recorded either as part of the purchase event, or as events that happened before the purchase.
Traditionally we record prices and estimated ship date as displayed to the customer inside the purchase. What if instead, we thought of the pricing decision and the ship date decision as events that happened before the purchase? and the purchase recorded that those events definitely happened before the purchase event?
We would be working toward establishing a different kind of event ordering. Did Justyna’s purchase happen before Edith’s? We can’t really say; they were at different locations, and neither influenced the other. That pricing decision though, that did influence Justyna’s purchase, so the price decision happened before the purchase.
This allows us to construct a more flexible ordering, something wider than a line.
Causal ordering
Consider a git history. By default, git log prints a line of commits as if they happened in that order — a total ordering.
But that’s not reality. Some commits happen before others: each commit I make is based on its parent, and every parent of that parent commit, transitively. So the parent happened before mine. Meanwhile, you might commit to a different branch. Whether my commit happened before yours is irrelevant. The merge commit brings them together; both my commit and yours happen before the merge commit, and after the parent commit. There’s no need for a total ordering here. The graph expresses that.
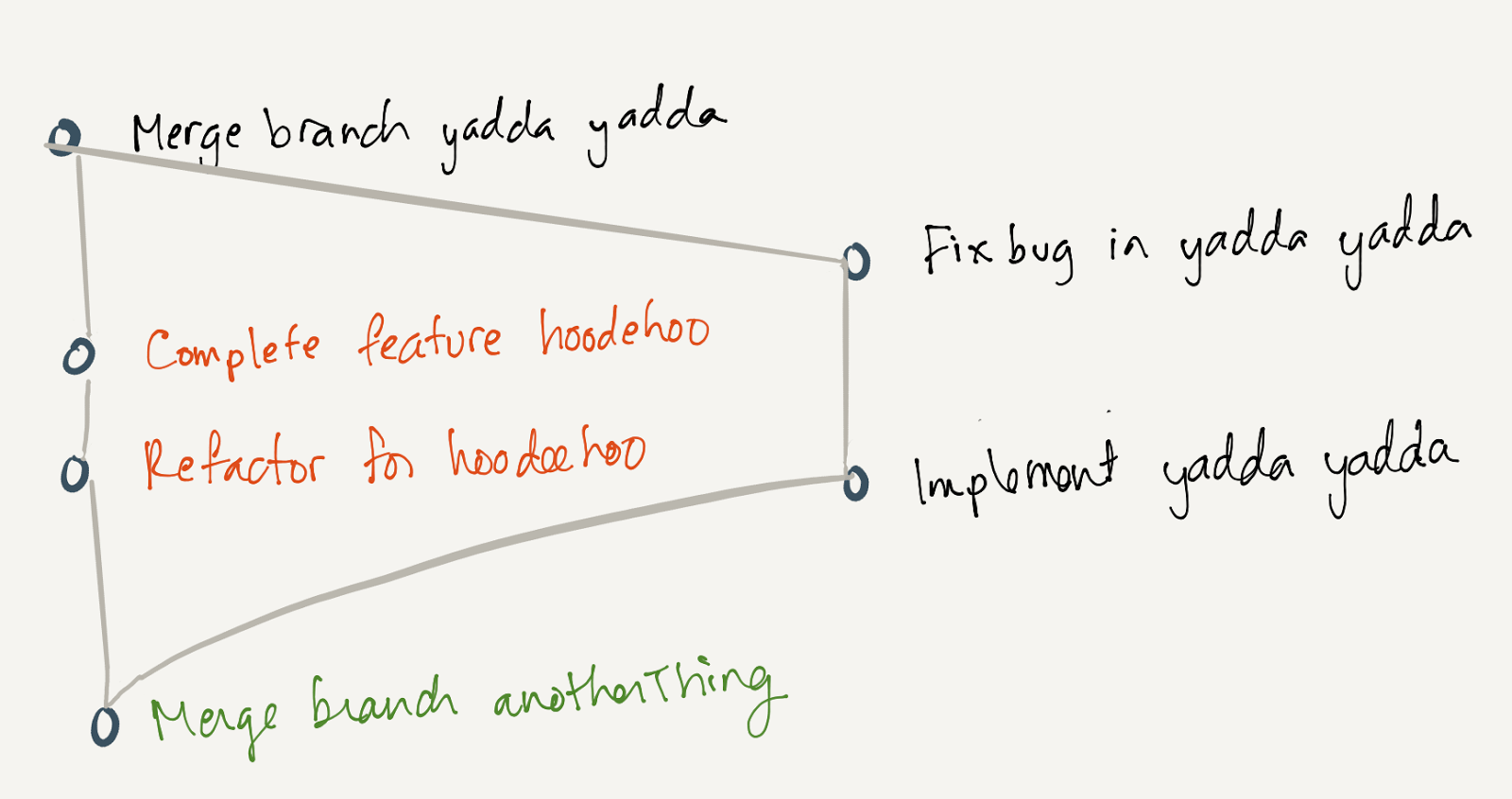
This is a causal ordering. It doesn’t care so much about clock time. It cares what commits I worked from when I made mine. I knew about the parent commit, I started from there, so it’s causal. Whatever you were doing on your branch, I didn’t know about it, it wasn’t causal, so there is no “before” or “after” relationship to yours and mine.
We can see the causal ordering clearly, because git tracks it: each commit knows its parents. The cause of each commit is part of the data in the commit.
Back to our retail example. If we record each event along with the events that caused it, then we can make a graph with enough of a causal ordering.

There are two reasons we want an ordering here: external consistency and internal legibility.
External Consistency
External consistency means that Justyna’s experience remains true. Some events are messages from our software system to Justyna (the price is $), and others are messages coming in (Confirm Purchase, Cancel Purchase). The sequence of these external interactions constrains any event ordering we choose. Messages crossing the system boundary must remain valid.
Here’s a more constricting example of external consistency: when someone runs a report and sees a list of transactions for the day, that’s an external message. That message is caused by all the transactions reported in it. If another transaction comes in late, it must be reported later as an amendment to that original report — whereas, if no one had run the report for that day yet, it could be lumped in with the other ones. No one needs to know that it was slow, if no one had looked.
Have you ever run a report, sent the results up the chain, and then had the central office accuse you of fudging the numbers because they run the same report (weeks later) and see different totals? This happens in some organizations, and it’s a violation of external consistency.
Internal Legibility
Other causal events are internal messages: we displayed this price because the pricing system sent us a particular message. The value of retaining causal information here is troubleshooting, and figuring out how our system works.
I’m using the word “legibility”[1] in the sense of “understandability:” as a person we have visibility into the system’s workings, we can follow along with what it’s doing. Distinguish its features, locate problems and change it.
If Justyna’s purchase event is caused by a ship date decision, and the ship date decision (“today”) tracked its causes (“the inventory system says we have one, with more arriving today”), then we can construct a causal ordering of events. If Edith’s purchase event tracked a ship date decision (“today”) which tracked its causes (“the inventory system says we have zero, with more arriving today”), then we can track a problem to its source. If in reality we only send one today, then it looks like the inventory system’s shipment forecasts were inaccurate.
How would we even track all this?
The global solution to causal ordering is: for every message sent by a component in the system, record every message received before that. Causality at a point-in-time-at-a-point-in-space is limited to information received before that point in time, at that point in space. We can pass this causal chain along with the message.
“Every message received” is a lot of messages. Before Justyna confirmed that purchase, the client component received oodles of messages, from search results, from the catalog, from the ad optimizer, from the review system, from the similar-purchases system, from the categorizer, many more. The client received and displayed information about all kinds of items Justyna did not purchase. Generically saying “this happened before, therefore it can be causal, so we must record it ALL” is prohibitive.
This is where business logic comes in. We know which of these are definitely causal. Let’s pass only those along with the message.
There are others that might be causal. The ad optimizer team probably does want to know which ads Justyna saw before her purchase. We can choose whether to include that with the purchase message, or to reconstruct an approximate timeline afterward based on clocks in the client or in the components that persist these events. For something as aggregated as ad optimization, approximate is probably good enough. This is a business tradeoff between accuracy and decoupling.
Transitive causality
How deep is the causal chain passed along with a message?
We would like to track backward along this chain. When we don’t like the result of Justyna and Edith’s purchase fulfillment, we trace it back. Why did the inventory system said the ship date would be today in both cases. This decision is an event, with causes of “The current inventory is 1” and “Normal turnover for this item is less than 1 per day”; or “The current inventory is 0” and “a shipment is expected today” and “these shipments usually arrive in time to be picked the same day.” From there we can ask whether the decision was valid, and trace further to learn whether each of these inputs was correct.
If every message comes with its causal events, then all of this data is part of the “Estimated ship date today” sent from the inventory system to the client. Then the client packs all of that into its “Justyna confirmed this purchase” event. Even with slimmed-down, business-logic-aware causal listings, messages get big fast.
Alternately, the inventory system could record its decision, and pass a key with the message to the client, and then the client only needs to retain that key. Recording every decision means a bunch of persistent storage, but it doesn’t need to be fast-access. It’d be there for troubleshooting, and for aggregate analysis of system performance. Recording decisions along with the information available at the time lets us evaluate those decisions later, when outcomes are known.
Incrementalness
A system component that chooses to retain causality in its events has two options: repeat causal inputs in the messages it sends outward; or record the causal inputs and pass a key in the messages it sends outward.
Not every system component has to participate. This is an idea that can be rolled out gradually. The client can include in the purchase event as much as its knows: the messages it received, decisions it made, and relevant messages sent outward before this incoming “Confirm Purchase” message was received from Justyna. That’s useful by itself, even when the inventory system isn’t yet retaining its causalities.
Or the inventory system could record its decisions, the code version that made them, and the inputs that contributed to them, even though the client doesn’t retain the key it sends in the message. It isn’t as easy to find the decision of interest without the key, but it could still be possible. And some aggregate decision evaluation can still happen. Then as other system components move toward the same architecture, more benefits are realized.
Conscious Causal Ordering
The benefits of a single, linear ordering of events are consistency, legibility, and visibility into what might be causal. A nonlinear causal ordering gives us more flexibility, consistency, a more accurate but less simplified legibility, and clearer visibility into what might be causal. Constructing causal ordering at the generic level of “all messages received cause all future messages sent” is expensive and also less meaningful than a business-logic-aware, conscious causal ordering. This conscious causal ordering gives us external consistency, accurate legibility, and visibility into what we know to be causal.
At the same time, we can have provenance for data displayed to the users or recorded in our databases. We can know why each piece of information is there, and we can figure out what went wrong, and we can trace all the data impacted by an incorrect past event.
I think this is something we could do, it’s within our ability today. I haven’t seen a system that does it, yet. Is it because we don’t care enough — that we’re willing to say “yeah, I don’t know why it did that, can’t reproduce, won’t fix”? Is it because we’ve never had it before — if we once worked in a system with this kind of traceability, would we refuse to ever go back?
[1] This concept of “legibility” comes from the book Seeing Like a State.
Sports games, Adventure games . The hot games section contains the most popular games online , Slither.io
Why no mention of CQRS and event sourcing? Great amount of this is amswered by projects like event sourcing.com
Why no mention of CQRS and event sourcing? Great amount of this is amswered by projects like event sourcing.com